Geloven Leren
Opinie en tools voor wie begaan is met het katholieke geloof
Eerste deel van Romeinse Catechismus online: de geloofsbelijdenis

Het digitaliseren gaat voorspoedig! Het eerste deel van de Romeinse Catechismus staat reeds online. Op dit adres kan je reeds een kijkje nemen:
trente.gelovenleren.net
In de verantwoording lees je meer over de achtergrond van de publicatie.
En natuurlijk is er ook een nieuwe kaart toegevoegd op Alledaags Geloven, waarop dagelijks een vers artikel uit de catechismus getoond wordt. Ik open elke dag de app en laat de Heilige Gest me leiden naar een—niet altijd vanzelfsprekend—geloofsfragmentje.

Mocht er iemand geïnteresseerd zijn in de technische procedure van het digitaliseren, zal ik die hieronder toevoegen. Ik moet zeggen dat ik zelf zeer enthousiast ben over het resultaat. Het vertrekpunt was een facsimile van een boek uit 1935, met telkens vier (verkleinde!) bladzijdes uit het origineel op één A4. Uiteindelijk moet ik per pagina maar een handvol spelfouten corrigeren! En dat allemaal met gratis tools. Het inscannen heeft me in de copyshop net geen 15 euro gekost, voor 200 blz. Er zijn mensen met duurdere hobby’s :)

Voorbeeld van een pagina uit de heruitgave van 1984
- pdf omgezet naar png-bestanden met pdftk
pdftk scan.pdf burst - er stonden telkens 4 pagina’s op 1 blad, die heb ik opgesplitst met Imagemagick:
convert bladxxx.png -crop 2x2+20+20@ +repage +adjoin bladxxx.png-%d.png - ik heb ScanTailor gebruikt om de tekst op de pagina’s recht te zetten en overal dezelfde marges toe te passen (ik weet niet of dat echt geholpen heeft met de OCR, maar zo heb ik ook een nette PDF als resultaat)
- de pagina’s terug gebundeld in een pdf
convert *.tif scan2.pdf - OCR toegepast met ocrmypdf (Python-script dat Tesseract gebruikt om OCR te doen)
ocrmypdf -l nld --remove-background --clean-final --optimize 3 scan2.pdf scan2-ocr.pdf
Dit script ‘embed’ de tekst in de PDF, zodat je de originele scan ziet, maar toch op tekst kan zoeken. - de tekst uit de PDF geëxporteerd als tekstbestand, voor correctie en verdere verwerking:
pdftotext scan2-ocr.pdf scan.txt - de spellingsfouten haal ik eruit met een spellingscorrectietool (aspell op Linux), waarmee ik meteen ook de oude Nederlandse spelling van de originele tekst rechtzet.
- de teksten worden beheerd in platte-tekstbestanden met Markdown-opmaak. Hugo bundelt alles tot één website en voor de layout zorgt het thema hugo-book, dat ik heb aangepast met enkele stijlelementen uit tufte-css.
Bovenstaande zijn allemaal commando’s op Linux, maar ik denk dat de belangrijkste tools ook op Windows beschikbaar zijn. Het is allemaal open source of alleszins gratis software en te vinden via je favoriete zoekmachine.
Verwante onderwerpen...
-
Homiletisch directorium teruggeënt op de praxis catechismi van de Romeinse catechismus
 Bij het digitaliseren van de Romeinse Catechismus (Catechismus Romanus Ex Decreto Concilii Tridentini, 1566, vert. …
Bij het digitaliseren van de Romeinse Catechismus (Catechismus Romanus Ex Decreto Concilii Tridentini, 1566, vert. …
-
De Mechelse Catechismus van Makeblijde
 Gisteren, 17 augustus, kwam ik op heiligen.net terecht op de vita van Lodewijk Makeblijde sj. Een heel uitvoerige …
Gisteren, 17 augustus, kwam ik op heiligen.net terecht op de vita van Lodewijk Makeblijde sj. Een heel uitvoerige …
-
Thomas van Aquino in een Euclidisch jasje
 De Nederlandse vertaling van de Summa Theologiae van Sint Thomas van Aquino is (gedeeltelijk) online gepubliceerd op de …
De Nederlandse vertaling van de Summa Theologiae van Sint Thomas van Aquino is (gedeeltelijk) online gepubliceerd op de …
-
Super-pastorale catechismus
 De katholieke Kerk zal over een goeie tien jaar haar 2000-jarig bestaan vieren. Ik mag hopen dat men zich hier en daar …
De katholieke Kerk zal over een goeie tien jaar haar 2000-jarig bestaan vieren. Ik mag hopen dat men zich hier en daar …
-
Het leven van Jezus in vogelperspectief
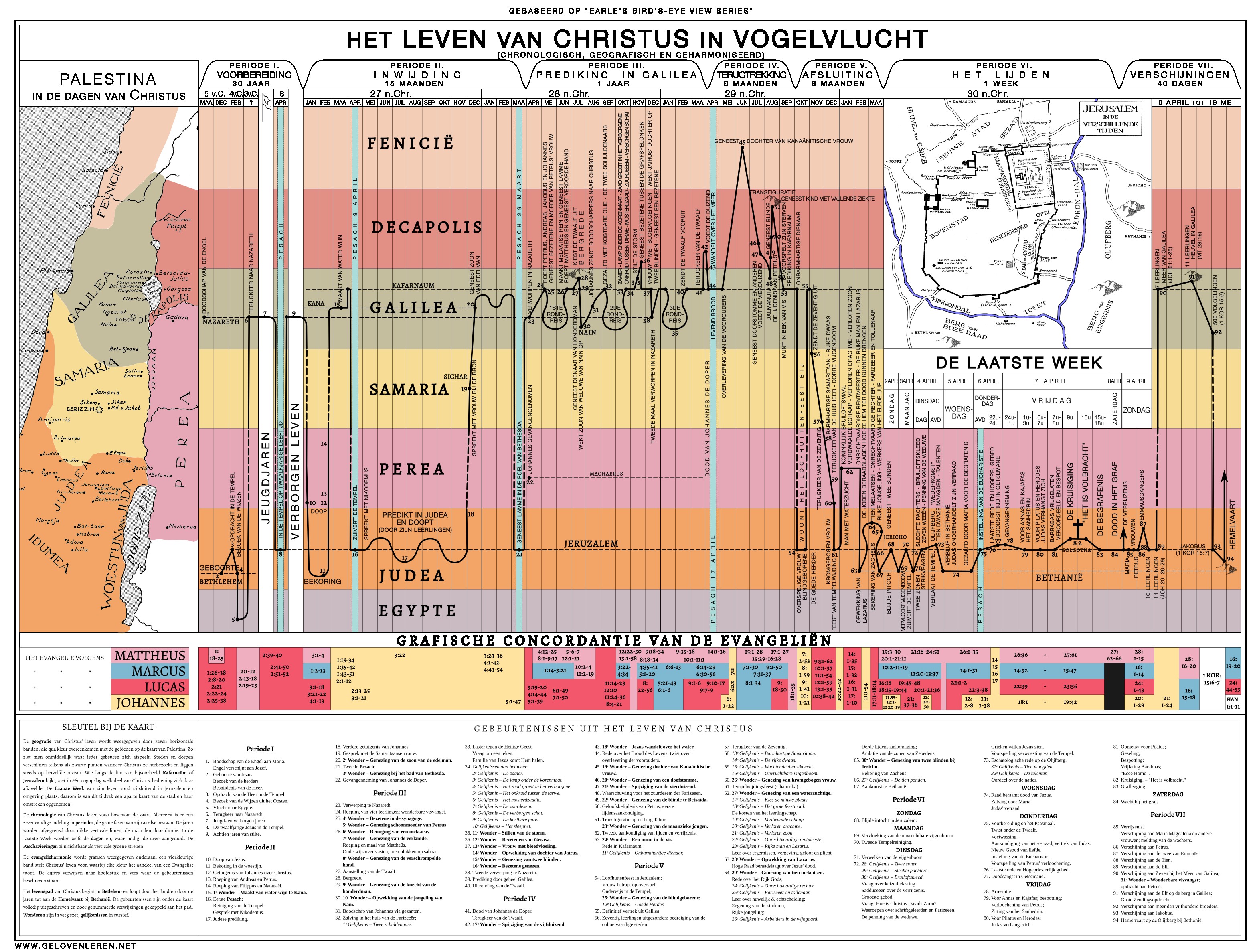 Over infografieken schreef ik vroeger regelmatig op dit blog, en soms maakte ik er zelf (na), bijvoorbeeld Gods …
Over infografieken schreef ik vroeger regelmatig op dit blog, en soms maakte ik er zelf (na), bijvoorbeeld Gods …