Geloven Leren
Opinie en tools voor wie begaan is met het katholieke geloof
Verzet je niet tegen wie kwaad doet... met een onverwachte wending
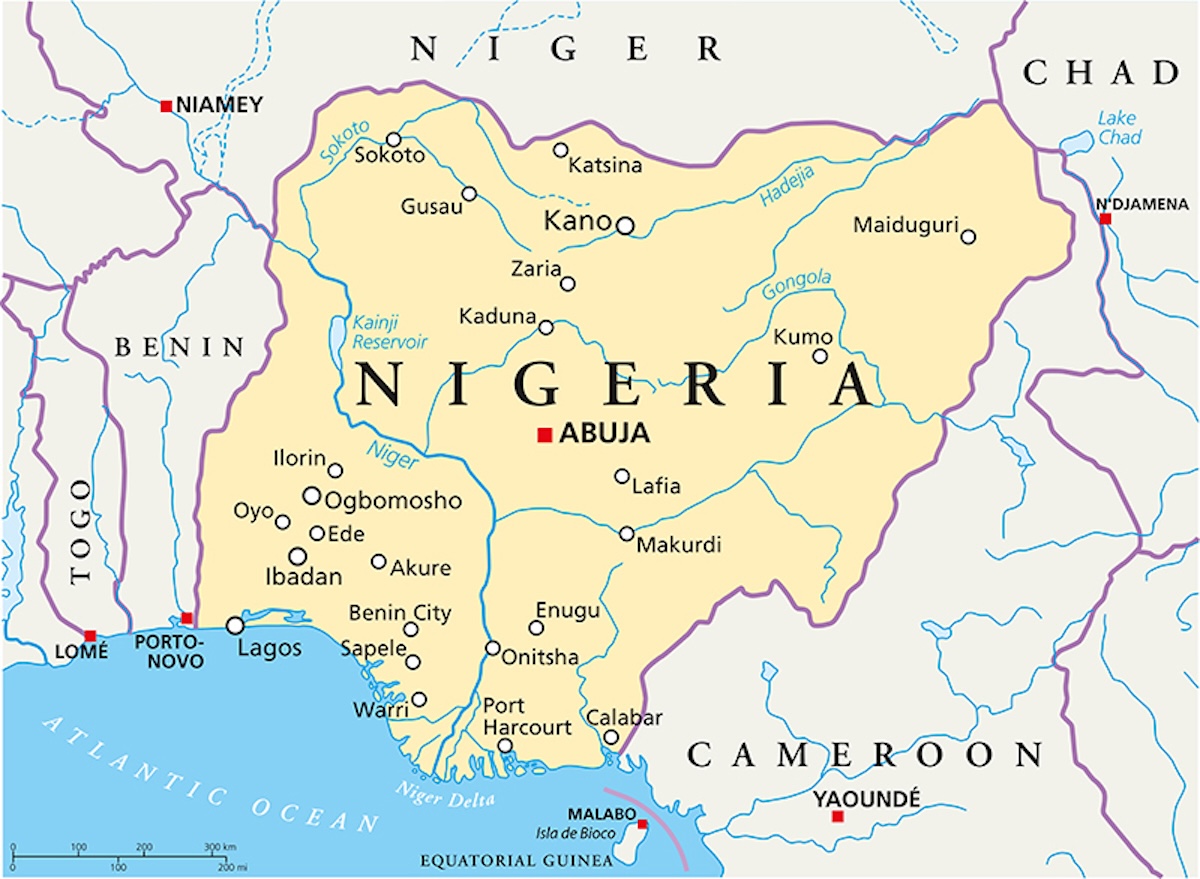 Vanmorgen was ik een beetje uit mijn hum, omdat ik op Aleteia, een katholieke nieuwssite, dit bericht las: "Nigeria …
Vanmorgen was ik een beetje uit mijn hum, omdat ik op Aleteia, een katholieke nieuwssite, dit bericht las: "Nigeria …
Catecheses van paus Leo XIV in het Nederlands op Alledaags Geloven
 Paus Leo XIV zet tijdens de wekelijkse algemene audiënties op woensdag de serie catecheses verder voor het jubileumjaar …
Paus Leo XIV zet tijdens de wekelijkse algemene audiënties op woensdag de serie catecheses verder voor het jubileumjaar …
Het eerste jaar van paus Franciscus
 De katholieke Kerk heeft een nieuwe Paus, Leo XIV. Het is dus tijd een woordje te wijden aan zijn voorganger, paus …
De katholieke Kerk heeft een nieuwe Paus, Leo XIV. Het is dus tijd een woordje te wijden aan zijn voorganger, paus …
70 bronnen voor alledaags geloof
 Wil je je geloof ontwikkelen, maar heb je geen tijd om er dikke boeken over te lezen, dan kan je op Alledaags Geloven …
Wil je je geloof ontwikkelen, maar heb je geen tijd om er dikke boeken over te lezen, dan kan je op Alledaags Geloven …
Thomas van Aquino over de godsdienstigheid
 Het werk aan de digitalisering van de Nederlandse vertaling van de Summa Theologiae gaat verder, op het tempo dat de …
Het werk aan de digitalisering van de Nederlandse vertaling van de Summa Theologiae gaat verder, op het tempo dat de …
Broodvermenigvuldigingstoneel
 Bijna tien jaar geleden heb ik me beziggehouden met het omzetten van evangelieverhalen tot kleine toneeltjes. Niet …
Bijna tien jaar geleden heb ik me beziggehouden met het omzetten van evangelieverhalen tot kleine toneeltjes. Niet …
Studiedag Thomas van Aquino op 5 april 2025 in Antwerpen
 Dit artikel dient ter kennisgeving van een welhaast historisch te noemen evenement dat onder de hoede van de …
Dit artikel dient ter kennisgeving van een welhaast historisch te noemen evenement dat onder de hoede van de …
Ik hou van contrareformatorische jezuïeten!
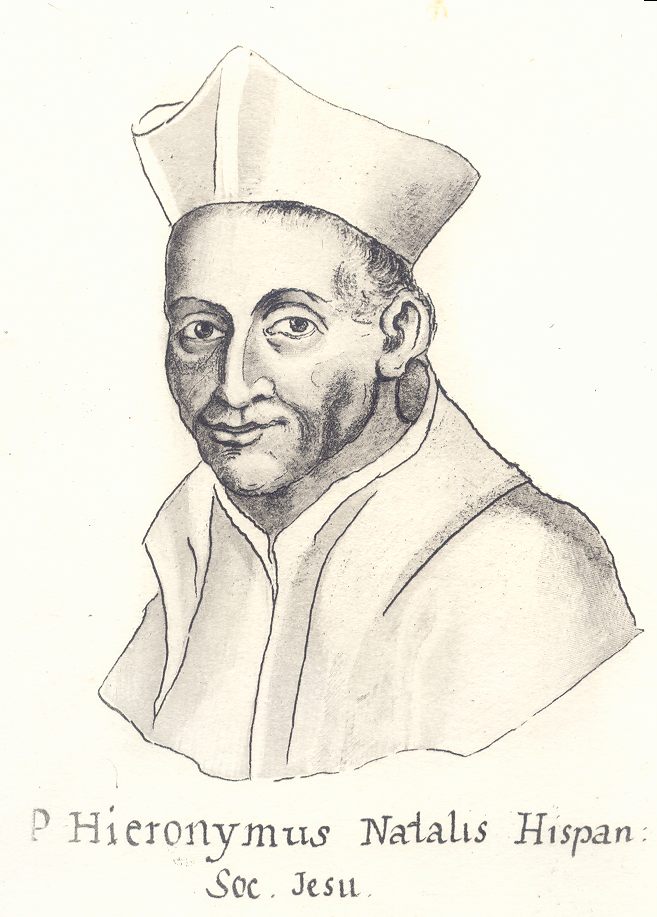 Als je beseft hoe vluchtig onze digitale wereld, is het verrassend dat er niet meer boeken gemaakt worden!
Met Alledaags …
Als je beseft hoe vluchtig onze digitale wereld, is het verrassend dat er niet meer boeken gemaakt worden!
Met Alledaags …
DDR-sfeertje in mijn buik
 Als ik maandag de tv aanzette om naar de inauguratie van Trump te kijken, stemde ik eerst af op VRT. Ik pikte in bij de …
Als ik maandag de tv aanzette om naar de inauguratie van Trump te kijken, stemde ik eerst af op VRT. Ik pikte in bij de …
Sanctifica: hoe technologie tradities nieuw leven inblaast
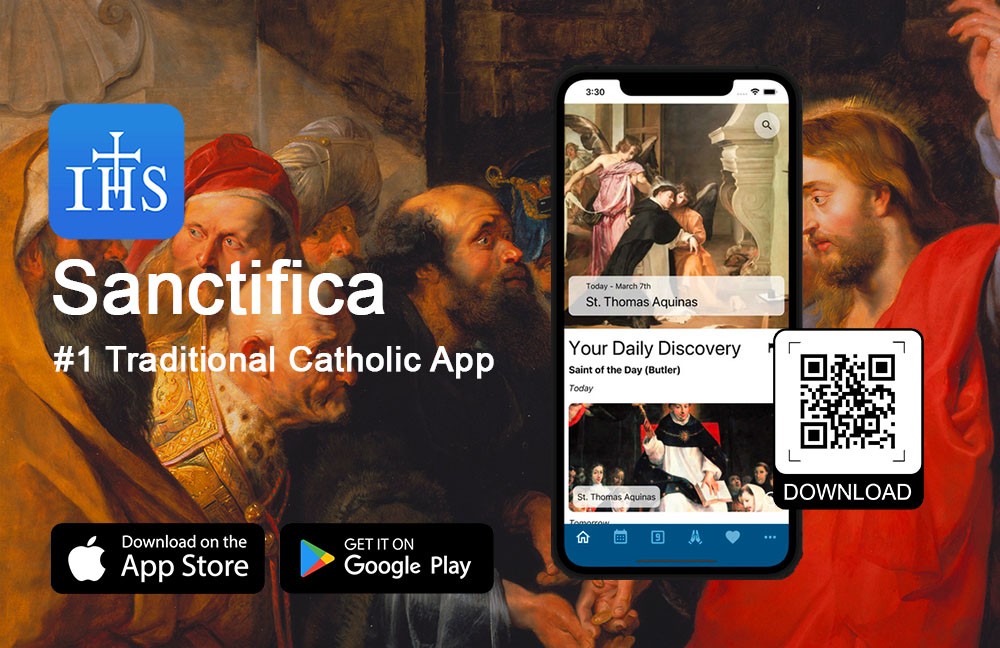 Met de app Sanctifica (https://sanctifica.com) verenigen traditionele katholieken eeuwenoude tradities en moderne …
Met de app Sanctifica (https://sanctifica.com) verenigen traditionele katholieken eeuwenoude tradities en moderne …